
PREDA:并行 VM 的最后一块拼图
确定性(Solana)、乐观(Monad)和(PREDA)异步并行化的优缺点一览


撰文:PREDA
文章来源:https://stellar-year-041.notion.site/PREDA-VM-7e939ea6e6c4498a9ef9d88c3e0762ac
Introduction
纵观计算机的并行史:第一个层次的并行性是指令级并行。指令级并行是 20 世纪最后 20 年体系结构提升性能的主要途径。指令级并行性可以在保持程序二进制兼容的前提下提高性能,这一点是程序员特别喜欢的。指令级并行分成两种。一种是时间并行,即指令流水线。指令流水线就像工厂生产汽车的流水线一样,汽车生产工厂不会等一辆汽车都装好以后再开始下一辆汽车的生产,而是在多道工序上同时生产多辆汽车。另一种是空间并行,即多发射,或者叫超标量。多发射就像多车道的马路,而乱序执行(Out-of-Order Execution)就是允许在多车道上超车,超标量和乱序执行常常一起使用来提高效率。在 20 世纪 80 年代 RISC 出现后,随后的 20 年指令级并行的开发达到了一个顶峰,2010 年后进一步挖掘指令级并行的空间已经不大。
第二个层次的并行性是数据级并行,主要指单指令流多数据流(SIMD)的向量结构。最早的数据级并行出现在 ENIAC 上。20 世纪六七十年代以 Cray 为代表的向量机十分流行,从 Cray-1、Cray-2,到后来的 Cray X-MP、Cray Y-MP。直到 Cray-4 后, SIMD 沉寂了一段时间,现在又开始恢复活力,而且用得越来越多。例如 X86 中的 AVX 多媒体指令可以用 256 位通路做四个 64 位的运算或八个 32 位的运算。SIMD 作为指令级并行的有效补充,在流媒体领域发挥了重要的作用,早期主要用在专用处理器中,现在已经成为通用处理器的标配。
第三个层次的并行性是任务级并行。任务级并行大量存在于 Internet 应用中。任务级并行的代表是多核处理器以及多线程处理器,是目前计算机体系结构提高性能的主要方法。任务级并行的并行粒度较大,一个线程中包含几百条或者更多的指令。
从并行计算发展的角度上来看,如今区块链所处的正是第一层次向第二层次转变的过程。主流区块链系统通常采用单链或者多链两种架构。单链,比如常见的 Bitcoin 和 Ethereum,整个系统只有一条链,链的每个节点执行完全相同的智能合约交易,维护完全一致的链上状态。每一个区块链节点内,智能合约交易通常采用串行执行,导致整个系统的吞吐率低。
最近出现的一些高性能区块链系统,虽然采用了单链架构,但同时也支持智能合约交易的并行执行。布朗大学和耶鲁大学的 Thomas Dickerson 和 Maurice Herlihy 等人在其 PODC’17 的论文中首先提出了基于 STM(Software Transactional Memory)方法的并行执行模型,该方法通过 optimistic parallelism(乐观并行)的方式将多条交易并行执行,如果交易在并行执行过程中遇到了状态访问冲突的问题,则通过 STM 去完成状态的回滚,然后再串行执行这些有状态冲突的交易。这类方法被应用到了多个高性能区块链项目当中,包括 Aptos、Sei 及 Monad 等等。与之对应,另一种并行执行模型基于 pessimistic concurrency(悲观并行)的方式,即交易被并行执行之前,需要检测交易访问的状态是否存在冲突,只有不存在冲突的交易才能够被并行执行。这类方法通常采用预先计算(pre-compute)的方式,利用程序分析工具对智能合约代码做静态分析并构建状态依赖关系,比如有向无环图(DAG)。当并发交易提交到系统以后,系统根据交易需要访问的状态以及状态之间的依赖关系来判断交易是否可以并行执行。只有相互之间没有状态依赖关系的交易才会被并行执行。该类方法被应用到了 Zilliqa(CoSplit 版本),Sui 等高性能区块链项目当中。上述的并行执行模型,都可以显著提升系统的吞吐率。这两种方案对应的是上文提到的指令级别并行。但是,这些工作存在两个问题:1)可扩展性问题和 2)并行语义表达问题,我们将在下文详细阐述。
Parallel Design
我们将使用典型的 Solana,Monad 项目的技术方案举例,拆解他们的并行架构设计,这包括并行化分类,数据依赖性等等会影响并行度和 TPS 的关键指标。
Solana
从较高的层面来看,Solana 的设计理念是区块链创新应该随着硬件的进步而发展。随着硬件根据摩尔定律不断改进,Solana 旨在从更高的性能和可扩展性中受益。 Solana 联合创始人 Anatoly Yakovenko 在五年多前最初设计了 Solana 的并行化架构,如今,并行性作为区块链设计原则正在迅速传播。
Solana 使用确定性并行化 (Deterministic Parallelization), 这来自 Anatoly 过去使用嵌入式系统的经验,开发者通常会预先声明所有状态。这使得 CPU 能够了解所有依赖关系,从而能够预取内存的必要部分。结果是优化了系统执行,但同样,它需要开发人员预先做额外的工作。在 Solana 上,程序的所有内存依赖项都是必需的,并在构造的事务(即访问列表)中进行说明,从而使运行时能够高效地并行调度和执行多个事务。
Solana 架构的下一个主要组件是 Sealevel VM,其支持根据验证器拥有的核心数量并行处理多个合约和交易。区块链中的验证者是网络参与者,负责验证和确认交易、提出新区块以及维护区块链的完整性和安全性。由于事务预先声明哪些帐户需要读写锁定,因此 Solana 调度程序能够确定哪些事务可以并发执行。正因为如此,在验证时,「区块生产者」或领导者能够对数千个待处理交易进行排序,并并行调度非重叠交易。
Monad
Monad 正在构建具有图灵完备的并行 EVM 第 1 层。 Monad 的独特之处不仅在于它的并行化引擎,还在于他们在后台构建的优化引擎。 Monad 对其整体设计采用了独特的方法,融合了几个关键功能,包括管道、异步 I/O、分离共识和执行以及 MonadDB。
与 Sei 类似,Monad 区块链使用「乐观并发控制(OCC)」来执行交易。当多个事务同时存在于系统中时,就会发生并发事务处理。该交易方法有两个阶段:执行和验证。
在执行阶段,事务被乐观地处理,所有读/写都临时存储在事务特定的存储中。此后,每个事务都将进入验证阶段,其中将根据先前事务所做的任何状态更改检查临时存储操作中的信息。如果事务是独立的,则事务并行运行。如果一个事务读取另一个事务修改的数据,就会产生冲突。
Monad 设计的一个关键创新是带有轻微偏移的流水线。该偏移量允许通过同时运行多个实例来并行化更多进程。因此,流水线用于优化许多功能,例如状态访问 Pipeline、交易执行 Pipeline、共识和执行内的 Pipeline 以及共识机制本身的 Pipelin,在下图对应的则是洗衣,烘干,叠衣服和放进衣柜。
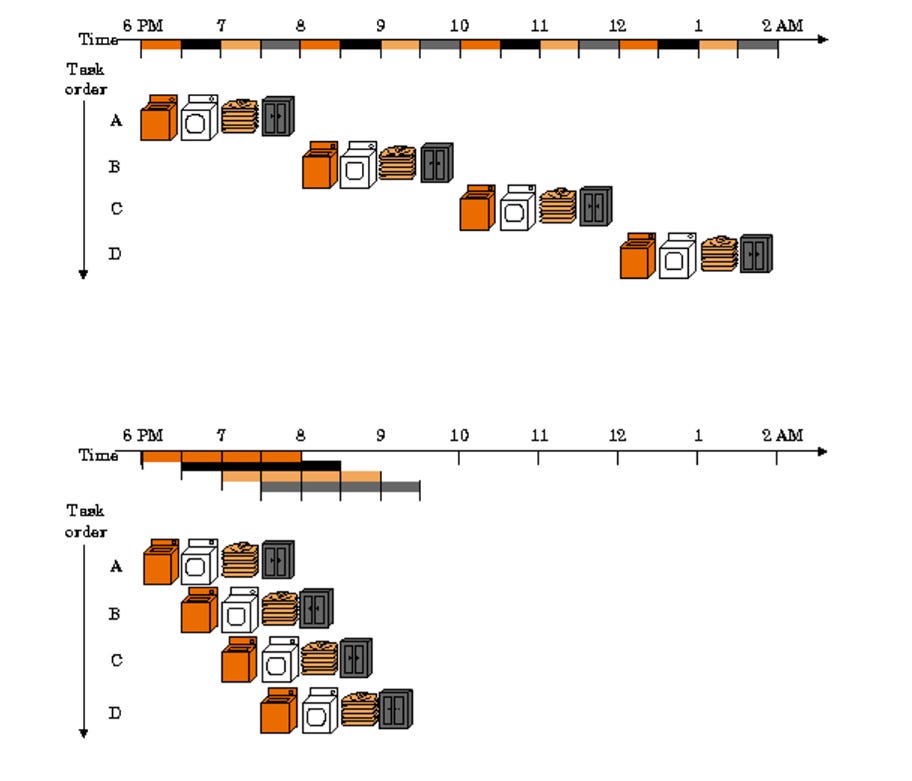
Monad 中,事务在块内线性排序,但目标是通过利用并行执行更快地达到最终状态。 Monad 使用乐观并行化算法来设计执行引擎。 Monad 的引擎同时处理交易,然后进行分析,以确保如果交易相继执行,结果将是相同的。如果有冲突,需要重新执行。这里的并行执行是一个相对简单的算法,但将其与 Monad 的其他关键创新相结合,使得这种方法变得新颖。这里需要注意的一件事是,即使发生重新执行,它通常也很便宜,因为无效事务所需的输入几乎总是保留在缓存中,因此这将是一个简单的缓存查找。重新执行一定会成功,因为您已经执行了块中之前的交易。
除了延迟执行之外,Monad 还通过分离执行和共识来提高性能,类似于 Solana 和 Sei。这里的想法是,如果您放宽在共识完成时完成执行的条件,则可以并行运行两者,从而为两者带来额外的时间。当然,Monad 使用确定性算法来处理这种情况,以确保其中一个不会跑得太远而无法赶上。
不论采用乐观并行还是悲观并行的执行方式,上述系统都采用 shared-memory 作为底层数据模型抽象,即不管有多少并行单元,并行单元都可以获取所有的数据(这里指区块链的所有链上数据),状态数据可以被不同的并行执行单元直接访问(即所有链上数据都可以被并行单元直接读写)。采用 shared-memory 作为底层数据模型的区块链系统,它的并发通常局限于单个物理节点(Solana),每一个物理节点的并发能力又受限于节点的计算能力,即物理线程的数量(假定每个线程支持一个虚拟机)。
这种节点内并行的方式只需要修改智能合约执行层的架构,不需要修改系统共识层的逻辑,从而非常适用于提升单链系统的吞吐率。因此,由于没有对数据存储进行分片,区块链网络中的每一个节点仍旧需要执行所有的交易并存储所有的状态。同时,相比于更适用于分布式扩展的 shared-nothing 架构,这些采用 shared-memory 作为底层数据模型抽象的系统,它们的处理能力无法做到水平扩展,即可通过增加物理机器的数量来实现系统状态存储以及执行能力的扩容,从而无法从根本上解决区块链的可扩展性问题。
那么是否有现成的解决方案呢?
Parallel Programming Model
在介绍 PREDA 之前,我们希望提出一个自然而然的问题是:为什么要用并行编程?在 20 世纪 70 年代、80 年代甚至 90 年代的一部分时间里,我们对单线程编程(或者称为串行编程)非常满意。你可以编写一个程序来完成一项任务。执行结束后,它会给你一个结果。任务完成,每个人都会很开心!虽然任务已经完成,但是如果你正在做一个每秒需要数百万甚至数十亿次计算的粒子模拟,或者正在对具有成千上万像素的图像进行处理,你会希望程序运行得更快一些,这意味着你需要更快的 CPU。
在 2004 年以前,CPU 制造商 IBM、英特尔和 AMD 都可以为你提供越来越快的处理器,处理器时钟频率从 16 MHz、20 MHz、66 MHz、100 MHz,逐渐提高到 200 MHz、333 MHz、466 MHz⋯⋯看起来它们可以不断地提高 CPU 的速度,也就是可以不断地提高 CPU 的性能。但到 2004 年时,由于技术限制,CPU 速度的提高不能持续下去的趋势已经很明显了。这就需要其他技术来继续提供更高的性能。CPU 制造商的解决方案是将两个 CPU 放在一个 CPU 内,即使这两个 CPU 的工作速度都低于单个 CPU。例如,与工作在 300 MHz 速度上的单核 CPU 相比,以 200 MHz 速度工作的两个 CPU(制造商称它们为核心)加在一起每秒可以执行更多的计算(也就是说,直观上看 2×200 > 300)。
听上去像梦一样的「单 CPU 多核心」的故事变成了现实,这意味着程序员现在必须学习并行编程方法来利用这两个核心。如果一个 CPU 可以同时执行两个程序,那么程序员必须编写这两个程序。但是,这可以转化为两倍的程序运行速度吗?如果不能,那我们的 2×200 > 300 的想法是有问题的。如果一个核心没有足够的工作会怎么样?也就是说,只有一个核心是真正忙碌的,而另一个核心却什么都不做?这样的话,还不如用一个 300 MHz 的单核。引入多核后,许多类似的问题就非常突出了,只有通过编程才能高效地利用这些核心。

在下图我们将Bob和Alice想象成两个淘金者,而淘金需要四个步骤:
🚚开车去矿场
⛏️采矿
🚚装载矿石
🔮储存并抛光

整个采矿过程由四个独立但有序的任务组成,每个任务需要 15 分钟。当 Bob 和 Alice 同时进行时,他们可以在 1 个小时内完成两倍的采矿工作量 —— 因为他们有自己的车,也可以共享道路,还可以分享打磨工具。
但是如果有一天,Bob 的采矿车发生了故障。他把采矿车留在修理厂,并把采矿的铁镐忘在了采矿车里内。回到加工厂的时候已经太迟了,但他们仍然有工作要做。只使用 Alice 的采矿车和里面的 1 把铁镐,他们还能每分钟采到两份矿石吗?
在上述的类比中,采矿的四个步骤就是线程,采矿车就是核心 (Core);矿则是智能合约需要执行的数据单元;铁镐则是执行单元;该程序由两个互相依赖的线程组成:在线程 1 执行结束之前,你无法执行线程 2。收获的矿产数量意味着程序性能。性能越高,Bob 和 Alice 掘金的收益就越高。可以将矿场看作内存,你可以从中获得一个数据单元(金矿),这样在线程 1 中摘取一颗矿石的过程就类似于从内存中读取数据单元。
现在,让我们看看如果 Bob 的采矿车发生故障后会发生什么。Bob 和 Alice 需要共用一辆车,这在最初并没有什么问题,而在保证采矿效率的前提下,采矿设备升级了以后,事情就变得不一样了;采矿可以装下矿石的数量就变成了整体效率的瓶颈,因为不管使用的采矿机器效率有多高,可以被送到打磨加工的矿石数量被 「矿车最大可容纳矿产」所制约。
这也是 Solana 的并行 VM 本质,核心共享。
核心共享
Solana 的最终设计元素是「管道化」。当数据需要通过一系列步骤进行处理并且不同的硬件负责每个步骤时,就会出现流水线操作。这里的关键思想是获取需要串行运行的数据并使用管道将其并行化。这些管道可以并行运行,每个管道阶段可以处理不同的事务批次。硬件(采矿车装载能力)的处理速度越高,并行化的 Throughout 就越高。如今,Solana 的硬件节点要求已经使得其节点运营商只有一种选择 —— 数据中心,这带来了效率但是背离了区块链的初衷。
数据依赖性未拆分(内存资源共享)
在升级了采矿车以后,因为挖矿产能跟不上,导致很多时候采矿车装不满。于是 Bob 又花高价采购了采矿机,提高了采矿的效率(执行单元升级)。同样的 15 分钟之内可以产出 10 份矿产了,但是因为矿石打磨工作还是像之前由手工完成,更多单位时间产生的矿石并没有办法转化成更多的金子,更多的矿石被挤压在了仓库;这个例子展示了当访问内存是我们程序执行速度的限制因素时会发生什么。处理数据的速度有多快(即核心运行速度)已无关紧要。我们将受到数据获取速度的限制。
较慢的 I/O 速度会严重困扰我们,因为 I/O 是计算机中速度最慢的部分,数据的异步读取(Asynchronous I/O)将变得至关重要。
即使 Bob 一把可以在 15 分钟内挖到 10 份矿产的采矿机,但如果存在内存访问竞争,他们仍然会被限制为每 15 分钟 2 份矿产。现有的并行区块链方案对该问题提出的解决方案分为两派 —— 悲观执行和乐观执行。
其中前者要求在数据写入和读取前要清楚地定义数据状态的依赖,这要求开发人员做预先的静态控制依赖假设,而在智能合约编程领域,这些假设往往都偏离了现实情况。后者对写入数据不做任何的假设和限制,如果发生了冲突则回滚。
以 Monad 的乐观执行方案举例:现实情况是大部分的工作量是交易执行,并行发生的场景并没有想象的那么多。下图是以太坊一天的 Gas Fee 消耗来源类型;你会发现,虽然这个分布没有流行的智能合约占比那么高,但是其实不同类型的交易类型确实存在分布没有那么均匀的情况。而乐观执行的并行逻辑在 Web2 时代是可行的,因为 Web2 应用的请求有很大一部分都是访问,而不是修改;比如淘宝和抖音,你其实没有太多机会去修改这些 APP 的状态。但是 Web3 领域则恰恰相反,大部分智能合约的请求恰恰就是修改状态 —— 更新账本,实际上这会带来预期之外更多的回滚,使得链不可用。

所以结论是 Monad 确实可以达到并行,但是并行度(Concurrency)存在理论上限,也就是落在 2 倍至 3 倍的区间,而不是其宣传的 100K。其次,这一上限没有办法通过增加虚拟机的方式进行扩容,也就是没有办法达到多核等于增加处理能力。最后也是老生常谈的问题,因为没有对数据进行分片,Monad 其实没有回答链上状态膨胀后带来的对节点的要求,以下是其对节点的要求,这已经超过了一个家庭电脑可以承载的极限,而随着其主网上线,如果不对数据进行分片,我们也许不可避免地看到 Monad 走向Solana的道路。而最后也是最重要的一点,乐观执行不适合区块链领域的并行。

采矿一段时间后,Bob 问了自己一个问题:「为什么我要等 Alice 回来以后再进行打磨?当他打磨时,我可以装车子,因为装车和打磨需要的时间完全相同,我们肯定不会遇到需要等待打磨空闲的状态。在 Alice 完成采矿之前,我会开车继续去挖矿,这样我们俩都可以是 100% 的忙碌。”」这个天才的想法让他们重新回到两倍的效率,甚至不需要额外的采矿车。重要的是,Bob 重新设计了程序,也就是线程执行的顺序,让所有的线程永远都不会陷入等待核心内部共享资源(比如采矿车及石镐)的状态。
这才是并行的正确版本,通过对智能合约的状态拆分,使得访问共享资源既不会导致某个线程进入排队,也不会因为数据 I/O 的 Pipeline 限制最终原子性达成的速度。
PREDA 模型通过将合约代码执行时刻对合约状态的访问结构暴露给执行层,使得执行层可以轻易合理调度,完全避免执行结果的回滚。这种并行模式又称异步并行。
异步并行

因为只有并行是异步的,增加线程才会到来线性的提升。而不会像前面的例子一样,升级了采矿车的容量但是因为采矿设备落后导致采矿车空跑。PREDA 的并行执行环境与 Moand,Solana 有最本质的区别 —— 就像多核 CPU 和 GPU 的区别一样,其共享核心的处理效率并不会是并行度的瓶颈,也不存在 I/O 读写时数据依赖性的问题,而更重要的是,PREDA 的并行模型的并行度会因为线程的增加而增加,与 GPU 有异曲同工之处。在区块链的逻辑中,线程的增加(VM)会降低全节点的硬件需求,从而达到在保证去中心化的前提下提升性能。

最后达到这一并行区块链的终局,行业内缺乏的除了是架构设计,还缺乏并行编程语言的语义表达。
并行编程语言的语义表达
就像 Nvidia 需要 CUDA,并行区块链也需要新的编程语言:PREDA。如今的智能合约的开发者并行语义进行表达,无法有效利用底层多链架构提供的支持(数据分片或执行分片或者兼而有之),无法实现通用智能合约交易的有效并行。所有系统在编程语言方面采用的都是 Solidity、Move、Rust 等传统的常见的智能合约编程语言。这些编程语言缺少并行语义表达能力,即,不具备类似于CUDA这样高性能计算或者大数据领域的并行编程模型和编程语言表达并行单元之间控制流与数据流的能力。
缺少适用于智能合约的并行编程模型及编程语言,会导致应用与算法从串行到并行的重构无法完成,导致应用与算法无法与底层具有并行执行能力的区块链系统适配,从而不能提高应用的执行效率以及区块链系统的整体吞吐率。
PREDA 提出的这一种分布式编程模型,通过程序化合约作用域对合约状态进行细粒度划分,并通过功能中继语义(Functional Relay) 将交易执行流分解后分布在多个并行执行引擎上执行。
该模型还通过程序化合约作用域(Programmable Scope)定义合约状态的划分方案,允许开发者根据应用的访问模式进行优化。通过异步功能中继,可以将交易执行流移动到需要访问状态的执行引擎上继续,实现了执行流程的移动而非数据的移动。
这种模型实现了合约状态的分布式划分和交易流量的分担,而不需要开发者关心底层多链系统的细节。实验结果表明,在 256 个执行引擎上 PREDA 模型可实现最高 18 倍的吞吐量提升,接近理论上的并行极限。通过使用分区计数器和可交换指令等技术,进一步提升了并行度。
Conclusion
区块链系统传统上使用单个顺序执行引擎(例如 EVM)来处理所有交易,从而限制了可扩展性。多链系统运行并行执行引擎,但每个引擎都处理智能合约的所有交易,无法在合约级别实现可扩展性。本篇文章论述了以 Solana 为代表的确定性并行的本质核心共享,以及以 Monad 为代表的乐观并行为何无法在真实的区块链应用场景中稳定运行 & 面临的高频率回滚的可能。并介绍了 PREDA 的并行执行引擎。PREDA 团队提出了一种新颖的编程模型,通过划分智能合约的状态并跨执行引擎分配交易流量来扩展单个智能合约。它引入了可编程合约范围来定义合约状态的划分方式。每个作用域都在专用的执行引擎上运行。异步功能中继(Asynchronous Functional Relay)用于分解事务执行流,并在所需状态驻留在其他地方时将其跨执行引擎移动。
这将事务逻辑与合约状态分区解耦,从而允许固有的并行性而无需数据移动开销。其并行模型既在智能合约层面拆分了状态,解耦了数据发布层面的依赖性,也提供了类似 Move 的 Multi-Threaded 执行引擎集群架构。更重要的是,其创新地推出了新的编程模型 PREDA,这也许会是区块链并行达成的最后一块拼图。
